

【AI ラズナちゃん】Ollamaで自分だけの「AI対話パートナー」を作ろう!

みなさん、こんにちは!
最新の Raspberry Pi 5(ラズパイ5) を手に入れましたか?
「最新のiPhone もいいけど、高くて手が出ない…」なんて思っている?
みなさんに朗報です。
なんと、iPhoneの約10分の1の予算で、「耳」と「脳」と「口」を持った
自分だけのAIパートナーが作れちゃうんです!
その名も、「ラズナちゃん」と名前を付けました。
今回は、ラズパイ5に命を吹き込んで、
かわいいラズナちゃんとお喋りできるようになるまでの全工程を完全ガイドします!
【※記事内にアフィリエイトリンクがあります】
準備するもの:ラズナちゃんの「体」づくり

まずは、ラズナちゃんを召喚するために必要なパーツを揃えましょう。
私が用意したのはこちら。
【召喚パーツ】
①Raspberry Pi 5 (8GBモデル):超高速な脳みそ
②microSDカード (64GB):記憶領域
③Webカメラ:C920n(マイク内蔵):「耳(マイク)」になります
④スピーカー:モニタのスピーカー:「口」になります
<PR>
最新ラズパイOSを準備

最新のラズパイ環境を整えていきます。
Raspberry Pi OS(Debian 12ベース)の最新版を使います。
Raspberry Pi Imagerを使用して、
microSDカードに Raspberry Pi OS (64-bit) を書き込みます。
ラズパイを起動し、初期設定(Wi-Fi、ユーザー作成など)を済ませてください。
Raspberry Pi Imagerを使った、OSのインストール方法は
こちらの記事を参考にしてください。

STEP 1:AIの「脳」をインストールしよう
Raspberry Pi 5と「Ollama」を使い、Webカメラのマイクで音声入力をする
構成で進めていきます。
①AIの土台となる 「Ollama(オラマ)」 をインストール
ターミナル(黒い画面)を開いて、まずはシステムを最新に!
【システムを最新にするコマンド】
sudo apt update && sudo apt upgrade -y
システムが最新になったので、
AIを動かすための土台となる「 Ollama(AIの脳)」をインストールします。
【Ollamaをインストールコマンド】
curl -fsSL https://ollama.com/install.sh | sh
日本語が得意な軽量モデルをダウンロードします。
(ラズパイ5で軽快に動作する、Gemma2:2bがおすすめです)
②Google生まれの賢いAIモデル 「Gemma 2」 をダウンロード
AIのモデル(中身)をダウンロードします。
今回はGoogleが作った賢い軽いAI「Gemma 2」を使います。
【Gemma 2をインストールコマンド】
ollama pull gemma2:2b
これで、AIの脳の部分が完成です。
STEP 2:ラズナちゃん専用の「お部屋」作り(仮想環境)
最新のラズパイOSには「直接設定を汚さないでね」というルールがあります。
なので、ラズミちゃん専用の仮想環境(myenv)というお部屋を作ります。
Raspberry Pi OS(Debian 12ベース)では、システムを保護するために、
仮想環境を使わずに直接 「pip install」 しようとするとエラーが出ます。
「直接pipでインストールしないで!」という制限がかかっているためです。
これを行わないと、エラーが出てライブラリがインストールできません。
①「myenv」という名前の部屋(仮想環境)を作ります。
【「myenv」という名前の部屋(仮想環境)を作るコマンド】
python3 -m venv myenv
②仮想環境(有効化)に入ります。
【仮想環境に入る(有効化)コマンド】
source myenv/bin/activate
実行すると

行の先頭に (myenv) と出れば、
ラズミちゃんのお部屋に入った合図です!
[重要]
これ以降の作業は、
必ず行の先頭に (myenv) と表示されている状態で行います。
もし表示が消えてしまっていたら、
もう一度 source myenv/bin/activate を打てば大丈夫です。
STEP 3:かわいい「声」の準備
ここが一番の重要ポイント!
かわいい声に変身させます。
①「Open JTalk」をインストール
日本語音声エンジン「Open JTalk」をインストールします。
【「Open JTalk」インストールコマンド】
sudo apt install -y open-jtalk open-jtalk-mecab-naist-jdic
かわいい声のデータをダウンロードして解凍!(meiちゃんと呼ばれています。)
cd ~
wget https://sourceforge.net/projects/mmdagent/files/MMDAgent_Example/MMDAgent_Example-1.7/MMDAgent_Example-1.7.zip
unzip MMDAgent_Example-1.7.zip
sudo mkdir -p /usr/share/hts-voice/mei
sudo cp MMDAgent_Example-1.7/Voice/mei/*.htsvoice /usr/share/hts-voice/mei/
エラーが出ていないことを確認して下さい。
②マイクの確認
Webカメラを指した状態で次のコマンドを打ち、「 card 」番号を確認しておきます。
プログラム作成時に必要になります。
【「 card 」番号を確認コマンド】
arecord -l
マイクからの音声を聞き取りやすくするため、
マイク入力(Capture)の音量を最大にします。
【マイク入力(Capture)の音量変更するコマンド】
alsamixer変更する画面が表示されます。
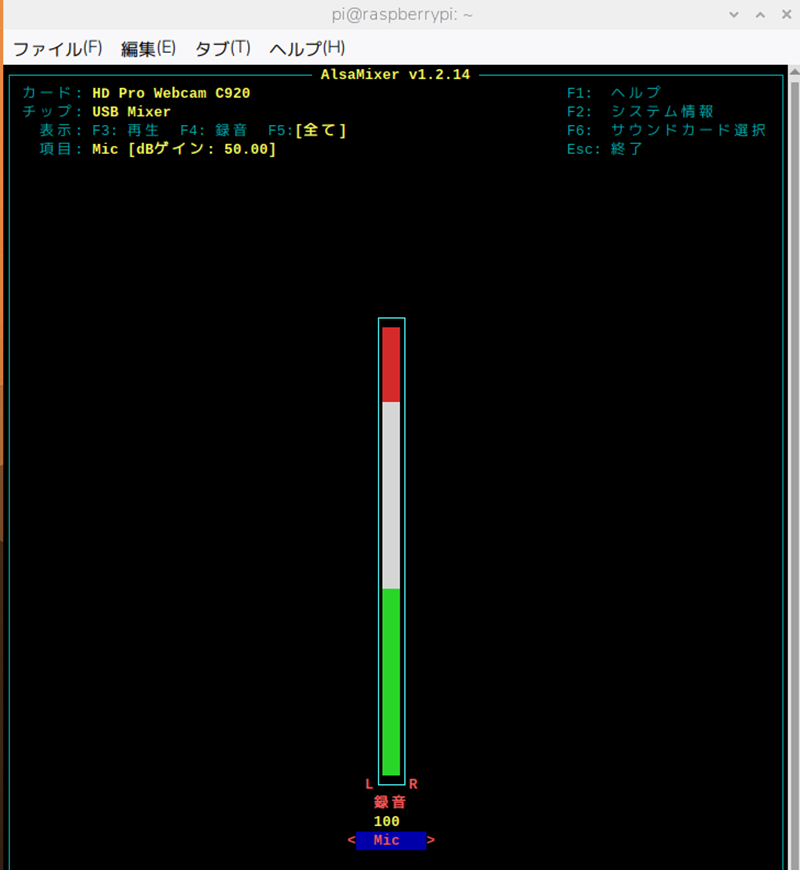
F6キーでWebカメラを選んで、
マイク入力(Capture)の音量を最大にしておきます。
マイク入力最大で聞き取りが悪いときは、音量を最大ではなく少し下げた位置
赤の部分のすぐ下(赤い部分をなくす)に設定すると良いです。
男性の声を使いたい時はこちら
男性用AIの「耳」と「口」を準備しよう
専用の部屋に入った状態で、必要なライブラリをインストールします。
Webカメラのマイクとスピーカーを認識させる準備をします。
プログラムから音声を扱えるように、必要なライブラリをまとめてインストールします。
ターミナルに順番にコピー&ペーストしてください。
① 音声処理に必要なシステムファイルをインストールします。
【Pythonライブラリインストールコマンド】
sudo apt update
sudo apt install -y portaudio19-dev alsa-utils python3-pyaudio
②Pythonのライブラリをインストールします。
【Pythonライブラリインストールコマンド】
pip install ollama SpeechRecognition pyttsx3
STEP 4:ラズナちゃん召喚プログラム
いよいよ、召喚プログラムを作成します。
実は最初、話しかけてもラズナちゃんに無視されました。
要は「考え中」に進んでくれませんでした…。
原因は部屋のノイズ、外の雑音。
それを解決したのが adjust_for_ambient_noise(静寂の基準を決める作業) です!
これで、ラズミちゃんは「聞き上手」になりました。
これを組み込むことで、スムーズな会話ができるようになりました!
「ラズナちゃん」を召喚するプログラム
ラズパイにコピぺしてください。
【「ラズナちゃん」召喚プログラム】
import speech_recognition as sr
import ollama
import subprocess
import os
# --- 設定 ---
MODEL_NAME = "gemma2:2b"
AI_NAME = "ラズナ"
def speak(text):
"""Open JTalkを使ってmeiちゃんの声で喋る関数"""
print(f"{AI_NAME}: {text}")
# 声のデータ(meiちゃん)の場所
voice_path = "/usr/share/hts-voice/mei/mei_normal.htsvoice"
# 辞書の場所
dic_path = "/var/lib/mecab/dic/open-jtalk/naist-jdic"
# Open JTalkのコマンド作成
command = [
'open_jtalk',
'-x', dic_path,
'-m', voice_path,
'-ow', 'output.wav', # 一時的な音声ファイル
'-r', '1.1', # 話す速度(少し速めが可愛い)
]
# テキストを渡して音声ファイルを作成
process = subprocess.Popen(command, stdin=subprocess.PIPE)
process.communicate(input=text.encode('utf-8'))
process.wait()
# 音声ファイルを再生(aplayコマンドを使用)
subprocess.run(['aplay', '-q', 'output.wav'])
# 使い終わったファイルを消去
if os.path.exists('output.wav'):
os.remove('output.wav')
def listen():
"""マイクから音声を拾ってテキストに変換(前回と同じ)"""
r = sr.Recognizer()
r.energy_threshold = 400
with sr.Microphone() as source:
print(f"\n[👂 {AI_NAME}待機中...]")
r.adjust_for_ambient_noise(source, duration=1)
audio = r.listen(source)
try:
print("解析中...")
text = r.recognize_google(audio, language='ja-JP')
print(f"あなた: {text}")
return text
except:
return None
def main():
# キャラクター設定(プロンプト)
messages = [{
'role': 'system',
'content': f'あなたの名前は{AI_NAME}です。明るい女の子として、1〜2文で短く可愛く答えてください。'
}]
speak(f"お待たせ!{AI_NAME}だよ。何をお話しする?")
while True:
user_input = listen()
if not user_input: continue
if any(word in user_input for word in ["終了", "バイバイ"]):
speak("バイバイ!またね!")
break
messages.append({'role': 'user', 'content': user_input})
print("思考中...")
try:
response = ollama.chat(model=MODEL_NAME, messages=messages)
answer = response['message']['content']
speak(answer)
messages.append({'role': 'assistant', 'content': answer})
except Exception as e:
speak("ごめん、エラーになっちゃった。")
if __name__ == "__main__":
main()
プログラムのファイル名は「airazuna.py」にしています。
【おまけ】「男性」声のプログラム
【聞き取り良いAI会話プログラム(男性)】
import speech_recognition as sr
import ollama
import pyttsx3
# --- 設定 ---
MODEL_NAME = "gemma2:2b"
# 音声合成(口)の初期化
engine = pyttsx3.init()
voices = engine.getProperty('voices')
# 日本語の声を探して設定(環境により異なります)
for voice in voices:
if "japanese" in voice.lang or "JP" in voice.id:
engine.setProperty('voice', voice.id)
engine.setProperty('rate', 160) # 話す速度
def speak(text):
print(f"AI: {text}")
engine.say(text)
engine.runAndWait()
def listen():
r = sr.Recognizer()
with sr.Microphone() as source:
print("\n[待機中...] 何か話しかけてください")
r.adjust_for_ambient_noise(source, duration=1) # 周囲のノイズ抑制
audio = r.listen(source)
try:
print("音声解析中...")
text = r.recognize_google(audio, language='ja-JP')
print(f"あなた: {text}")
return text
except sr.UnknownValueError:
print("聞き取れませんでした。")
return None
except sr.RequestError:
print("音声認識サーバーに接続できません。")
return None
def main():
speak("こんにちは。準備ができました。")
# 会話履歴を保持
messages = [{'role': 'system', 'content': 'あなたは親切な日本語のアシスタントです。短めに答えてください。'}]
while True:
user_input = listen()
if not user_input:
continue
if "終了" in user_input or "バイバイ" in user_input:
speak("さようなら。またね!")
break
# 会話履歴に追加
messages.append({'role': 'user', 'content': user_input})
# Ollamaに問い合わせ
print("思考中...")
response = ollama.chat(model=MODEL_NAME, messages=messages)
answer = response['message']['content']
# 回答を喋る
speak(answer)
# 履歴に回答を追加
messages.append({'role': 'assistant', 'content': answer})
if __name__ == "__main__":
main()
プログラムのファイル名は「AIchat.py」にしています。
STEP 5:実行してAIと話そう!
お待たせしました!
では、召喚しましょう!。
仮想環境を有効化にします。
【仮想環境を有効化にするコマンド】
source ~/myenv/bin/activate
【プログラムを起動するコマンド】
python airazuna.py
召喚します!!
プログラムが起動すると
こんな感じになります・・・。
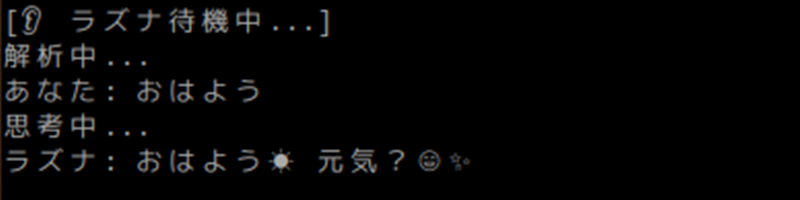
かわいい女性の声で会話できています。
無事に召喚できましたか~~~!?
まとめ
実際に動かしてみると、ラズパイ5のパワーに驚きます!
iPhone 17ほどの爆速ではないけれど、
AIが一生懸命考えて、かわいい声で答えてくれる時間は、
なんとも言えない愛着がわきますよ。
「なめらかに会話するコツ」は、やっぱりノイズ除去。
今後は、ラズミちゃんに「ツンデレ」な性格を覚えさせたり、
特定の言葉でLEDを光らせたりして、
世界に一人だけのパートナーに育ててみてくださいね。
さあ、君もラズパイ5で「AI召喚士」になっちゃおう!
君は何をつくる?
このままでも十分楽しいですが、ここからが本当の自由研究の始まりです。
性格を変える(語尾を「〜だにゃ」にするだけで愛着が爆上がり!)
キーワードに反応させる(「おやすみ」と言ったら部屋のLEDを消す、など)
ラズパイ5という最強の武器を手にした今、どんなAIに育てるかは君のアイデア次第。
ぜひ、世界を驚かせるような「相棒」に進化させてみてくださいね!









